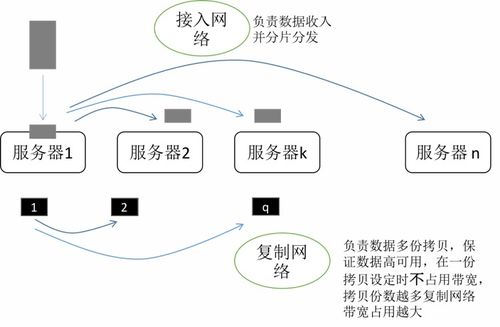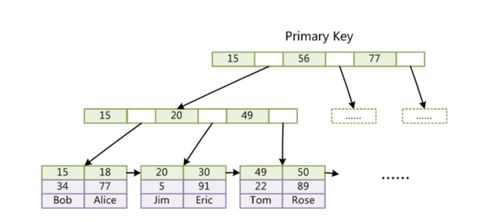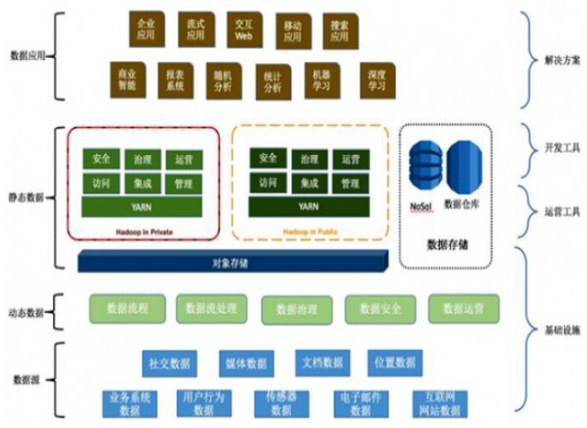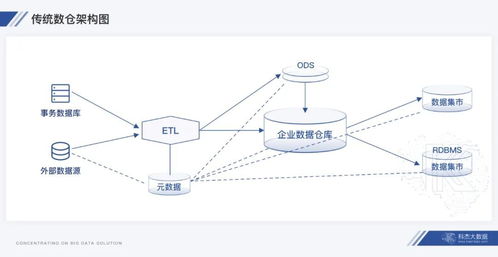
在數(shù)據(jù)驅(qū)動的時代,數(shù)據(jù)處理與存儲架構(gòu)的演進(jìn)從未停歇。過去,企業(yè)常在數(shù)據(jù)倉庫(Data Warehouse)與數(shù)據(jù)湖(Data Lake)之間艱難抉擇:數(shù)倉強(qiáng)于結(jié)構(gòu)化數(shù)據(jù)的高性能分析,但擴(kuò)展性、成本及半/非結(jié)構(gòu)化數(shù)據(jù)處理能力有限;數(shù)據(jù)湖能以低成本存儲海量原始數(shù)據(jù),格式靈活,但易淪為“數(shù)據(jù)沼澤”,缺乏可靠的數(shù)據(jù)治理與高效的查詢性能。如今,一種融合二者優(yōu)勢的新范式——湖倉一體(Lakehouse)正冉冉升起,它并非讓數(shù)倉或數(shù)據(jù)湖“退出群聊”,而是引領(lǐng)它們走向更高階的融合與統(tǒng)一,成為企業(yè)數(shù)據(jù)架構(gòu)進(jìn)化的下一站“燈塔”。
湖倉一體架構(gòu)的核心在于,在低成本、可擴(kuò)展的數(shù)據(jù)湖存儲層之上,構(gòu)建了類似數(shù)據(jù)倉庫的數(shù)據(jù)管理與事務(wù)處理能力。它通過開放式格式(如Apache Parquet、Delta Lake、Iceberg等)存儲數(shù)據(jù),并支持ACID事務(wù)、數(shù)據(jù)版本管理、完善的元數(shù)據(jù)層以及統(tǒng)一的訪問接口。這意味著,企業(yè)可以在同一個平臺上,同時完成數(shù)據(jù)工程、數(shù)據(jù)科學(xué)、機(jī)器學(xué)習(xí)與商業(yè)智能分析,無需在數(shù)倉與數(shù)據(jù)湖之間進(jìn)行繁瑣、易錯的數(shù)據(jù)遷移與復(fù)制。
這一架構(gòu)為數(shù)據(jù)處理和存儲支持服務(wù)帶來了根本性變革:
- 統(tǒng)一性與簡化治理:湖倉一體打破了“湖”與“倉”之間的壁壘,提供了一個單一的數(shù)據(jù)源頭。數(shù)據(jù)一旦入湖,即可被各類分析與機(jī)器學(xué)習(xí)工具直接消費(fèi),極大簡化了數(shù)據(jù)管道,減少了數(shù)據(jù)冗余。統(tǒng)一的安全、治理與元數(shù)據(jù)管理策略貫穿始終,有效提升了數(shù)據(jù)質(zhì)量、一致性與合規(guī)性。
- 性能與成本的最優(yōu)解:它繼承了數(shù)據(jù)湖使用低成本對象存儲(如云上S3、ADLS)的優(yōu)勢,同時通過智能緩存、索引優(yōu)化、數(shù)據(jù)布局優(yōu)化(如Z-Ordering)及向量化查詢引擎等技術(shù),實現(xiàn)了接近甚至超越傳統(tǒng)數(shù)倉的交互式查詢性能。企業(yè)不再需要為性能和成本做痛苦權(quán)衡。
- 支持多樣化的數(shù)據(jù)與工作負(fù)載:無論是結(jié)構(gòu)化的交易數(shù)據(jù),還是半結(jié)構(gòu)化的日志、JSON,乃至非結(jié)構(gòu)化的圖像、文本,湖倉一體都能原生支持。它無縫銜接了從ETL/ELT批處理、實時流處理到高級分析與AI模型訓(xùn)練的全場景工作負(fù)載,賦能更廣泛的數(shù)據(jù)驅(qū)動創(chuàng)新。
- 開放的生態(tài)系統(tǒng):基于開放格式和標(biāo)準(zhǔn)(如Apache Spark、Presto/Trino),湖倉一體避免了廠商鎖定。用戶可以選擇最適合的工具鏈,從計算引擎到BI工具,構(gòu)建靈活、可互操作的數(shù)據(jù)棧。
湖倉一體并非終點(diǎn),而是數(shù)據(jù)架構(gòu)持續(xù)演進(jìn)的關(guān)鍵里程碑。它標(biāo)志著數(shù)據(jù)處理范式從“分離與復(fù)制”走向“統(tǒng)一與融合”。對于尋求數(shù)字化轉(zhuǎn)型的企業(yè)而言,擁抱湖倉一體意味著構(gòu)建一個既能應(yīng)對當(dāng)前海量、多態(tài)數(shù)據(jù)挑戰(zhàn),又能靈活適應(yīng)未來AI/ML爆發(fā)式增長需求的現(xiàn)代化數(shù)據(jù)基座。數(shù)倉與數(shù)據(jù)湖的精華在此匯聚,共同照亮數(shù)據(jù)價值深度挖掘與業(yè)務(wù)敏捷創(chuàng)新的前行之路。